What is a Mobile AI Agent? The 2026 Guide
Natalie
06/12/2026
Learn how a mobile AI agent plans tasks, uses apps and permissions, and improves smartphone workflows with safer mobile automation.
Learn how a mobile AI agent plans tasks, uses apps and permissions, and improves smartphone workflows with safer mobile automation.
Visa & OpenAI enable AI agent payments, Mastercard launches AI solutions, NVIDIA's Nemotron outperforms. Latest AI news & breakthroughs.
Compare AI agent frameworks by runtime control, scoring state, tools, observability, evals, security, cost, and deployment readiness.
LLM news: UK's first NHS healthcare AI, Hades malware threats, NVIDIA Blackwell speeds, 5M token breakthrough. Read latest AI updates.
Compare AI coding model 2026 choices by benchmarks, repo workflow, testing, cost, and review controls to select the right stack.
AI agent hardware revolution: Microsoft Solara, Nvidia agentic PCs, $35B Anthropic funding. Latest AI tech news & breakthroughs →
Learn how an AI agent hardware device uses edge AI, permissions, and integrations to turn intent into safe, auditable actions.
Compare Gemini vs Claude enterprise 2026 by workflow fit, governance, deployment, and TCO to choose the right model strategy.
Perplexity vs ChatGPT vs Claude research 2026: compare retrieval, analysis, synthesis, citations, and verification workflows.
NVIDIA unveils Vera CPU for AI agents, Anthropic files IPO, and major funding rounds reshape AI hardware market. Get the latest updates.
Claude-family models and Claude Code are the strongest overall AI coding model 2026 choice for complex repository work, while GitHub Copilot remains the safest daily-driver developer assistant for mainstream teams that want tight IDE and GitHub workflow integration.
That answer needs one important clarification: the best AI model for coding is not always the best coding tool. Benchmarks measure raw capability, but real developer results depend on repo context, test execution, pull request quality, security controls, pricing, latency, and how much human review the workflow requires.

The most useful AI coding model 2026 ranking separates three things that are often mixed together:
A frontier model can perform well on coding benchmarks and still feel frustrating if it cannot inspect a repository, run tests, create clean diffs, or fit into a team review process. The reverse is also true: a slightly weaker model inside a polished developer AI assistant can deliver better day-to-day productivity because it is always available in the editor, understands project context, and supports normal pull request habits.
For 2026, the strongest overall recommendation is:
| Rank | AI coding model 2026 choice | Best for | Why it ranks here |
|---|---|---|---|
| 1 | Claude-family models with Claude Code | Deep refactoring, debugging, repo reasoning | Strong SWE-bench-style signals and excellent terminal-agent workflow |
| 2 | OpenAI GPT/Codex family | Cloud coding tasks, codebase Q&A, PR proposals | Strong agent ecosystem and broad coding capability |
| 3 | GitHub Copilot | Daily professional development | Best mainstream IDE and GitHub workflow fit |
| 4 | Gemini models with Google coding tools | Google Cloud teams, long-context workflows | Strong cloud ecosystem and enterprise relevance |
| 5 | DeepSeek coding models | Budget-sensitive API coding | Strong cost-performance positioning |
| 6 | Mistral Codestral and Devstral | Flexible model deployment and coding-specific use | Good fit for teams evaluating open or controllable stacks |
| 7 | Aider with selected models | CLI pair programming and test-driven edits | Transparent, model-flexible, practical for power users |
| 8 | Replit Agent | Greenfield apps and prototypes | Low setup friction for app creation |
| 9 | Devin-style autonomous agents | Async engineering delegation | High autonomy, but review burden remains significant |
| 10 | Hugging Face coding model ecosystem | Model discovery and self-hosting experiments | Broad choice, variable quality |
This ranking does not mean one tool should replace every other option. A professional team might use GitHub Copilot for routine editor assistance, Claude Code for complex refactors, Codex-style cloud agents for scoped background tasks, and open-weight models for internal experiments.
The most reliable pattern is not "pick one model forever." It is "choose the right AI model for coding for each development workflow."
Benchmarks matter, but they need context. The best AI model for developers should perform well on real coding tasks, not just short algorithm puzzles.
The most important benchmark categories in 2026 are:
| Benchmark | What it measures | Why it matters | Main limitation |
|---|---|---|---|
| SWE-bench | Real GitHub issue resolution | Strong proxy for repo-level bug fixing | Does not fully measure security, maintainability, or team review burden |
| SWE-bench Verified-style evaluations | Human-validated real issue tasks | More reliable than broad unfiltered issue sets | Scores vary by harness and model configuration |
| LiveCodeBench | Newer coding problems | Reduces benchmark contamination | Less representative of large production repositories |
| HumanEval | Function-level Python generation | Simple baseline for code generation AI | Saturated by frontier models |
| MBPP | Basic Python programming tasks | Useful entry-level coding benchmark | Too narrow for production engineering |
| Aider leaderboards | Practical code editing through a CLI workflow | Useful for diff-based real file changes | Tool-specific and not a full enterprise benchmark |
Recent SWE-bench-style leaderboard snapshots from the research report showed Claude-family models, OpenAI models, and Gemini-class models near the top, but exact scores varied across sources such as SWE-bench, LLM Stats, and Vals AI. That variation is important. A score from one harness is not a permanent truth; it is a snapshot affected by date, model settings, task selection, scaffolding, and tool access.
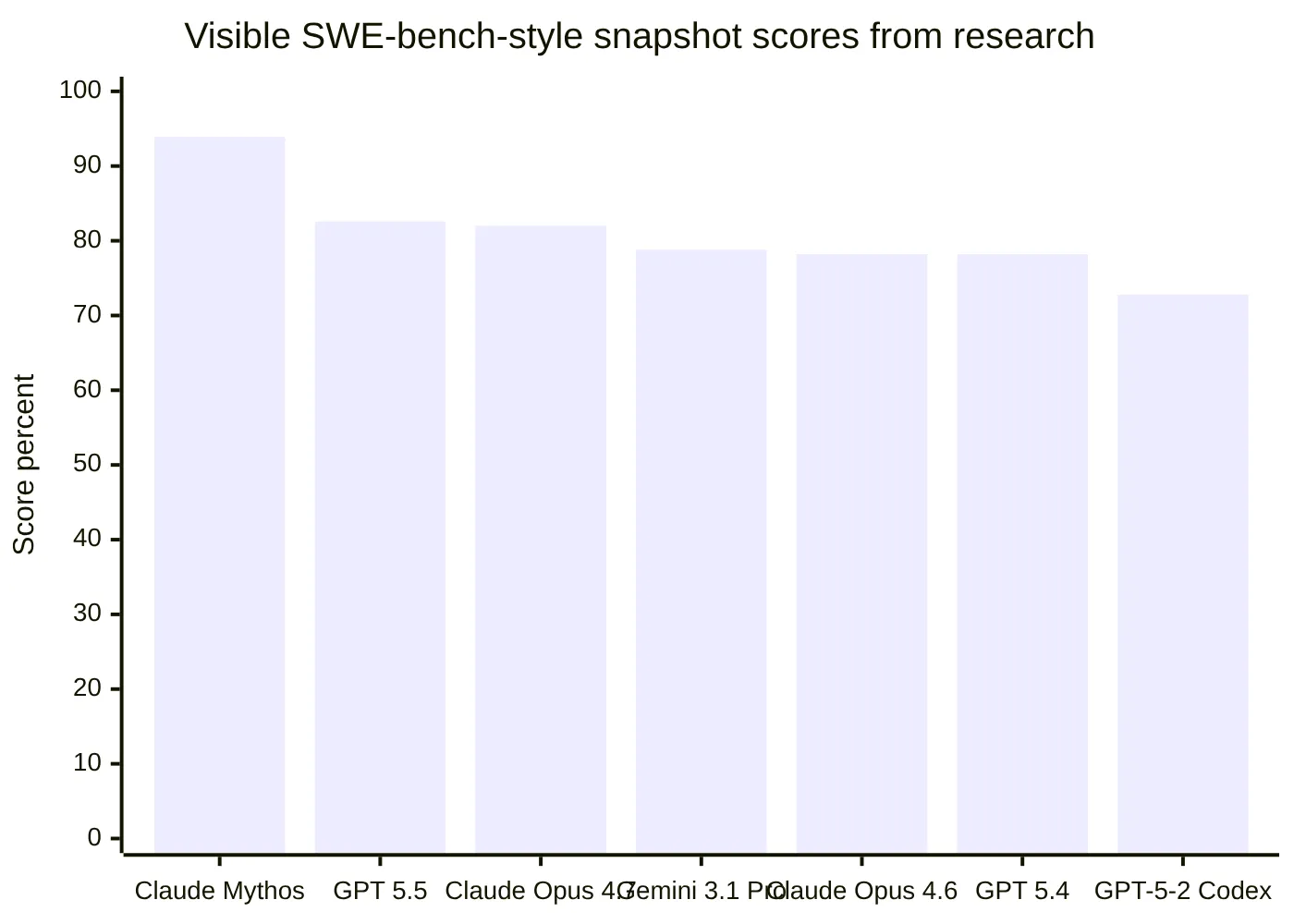
The chart should be treated as a directional snapshot, not a final leaderboard. For any production buying decision, teams should recheck the live benchmark pages and run internal evaluations on their own repositories.
A practical AI coding tool comparison should weight evidence like this:
| Evaluation criterion | Suggested weight | Why it matters |
|---|---|---|
| Code generation quality | 15% | Determines first-pass usefulness |
| Debugging and bug fixing | 15% | Core developer pain point |
| Repository-level reasoning | 15% | Essential for mature codebases |
| Agentic task completion | 12% | Measures multi-step execution |
| IDE, CLI, and Git workflow fit | 10% | Determines daily adoption |
| Long-context handling | 8% | Helps with large repos |
| Cost and value | 8% | Critical for teams and startups |
| Speed and latency | 6% | Affects flow state |
| Reliability and safety | 6% | Prevents dangerous or noisy changes |
| Enterprise readiness | 5% | Needed for governed rollout |
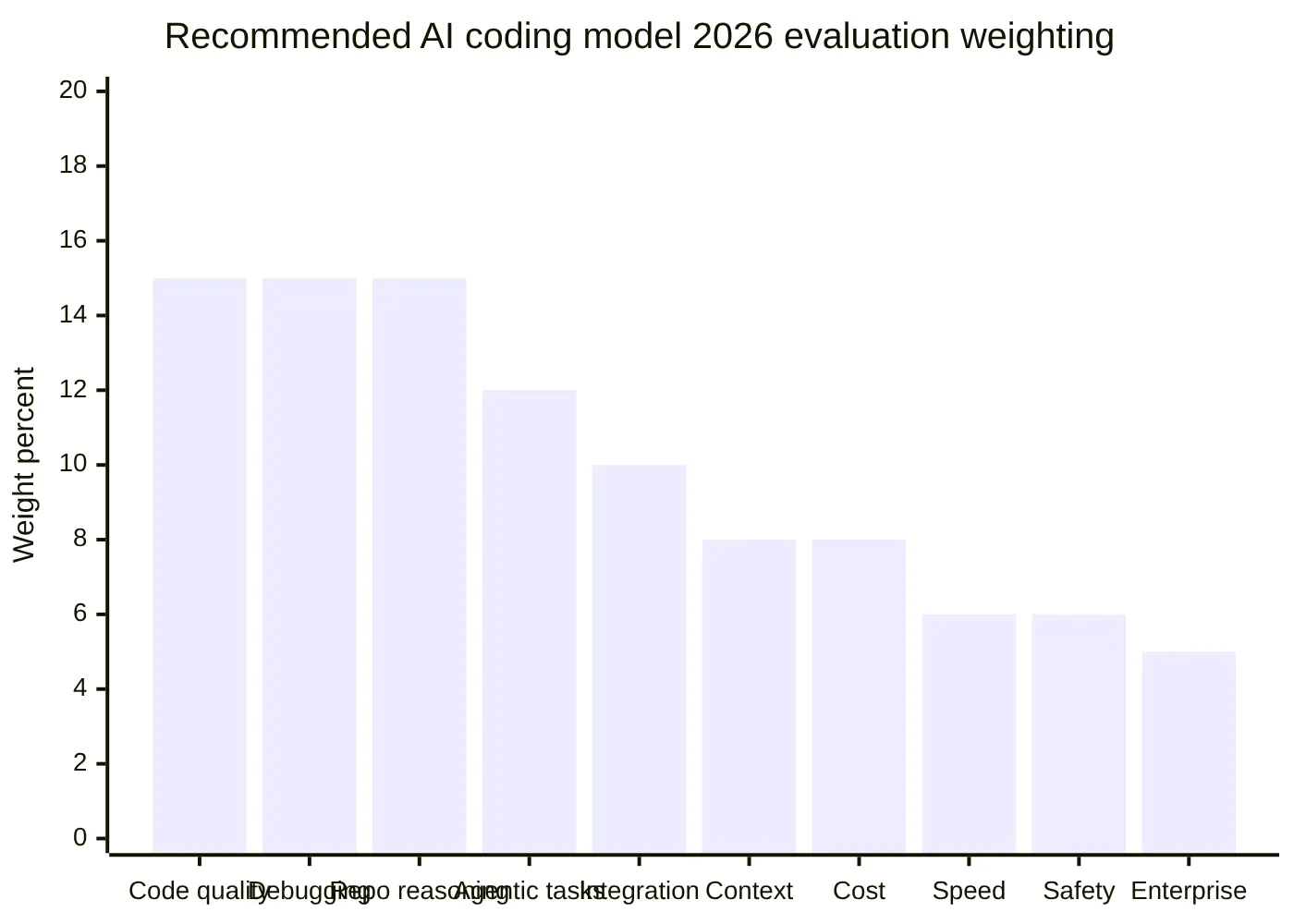
The conclusion from benchmark evidence is clear: Claude-family models deserve the top overall AI coding model 2026 position for complex repo work, but GitHub Copilot deserves a separate top recommendation for mainstream workflow adoption. Benchmarks answer "which model solved the task?" Developer results answer "which assistant helped the team ship better code with less friction?"
A useful AI coding model 2026 ranking should start with use cases because developers do not all need the same kind of assistant. A solo founder building a prototype, a senior engineer refactoring a service, and an enterprise platform team managing security reviews have different requirements.

Claude-family models with Claude Code are the best overall choice for complex repository-level work. The research report highlights strong SWE-bench-style positioning, developer reports that praise Claude Code for refactoring and debugging, and the importance of terminal-native workflows for real codebase edits.
Best fit:
Main caution: Claude Code-style workflows can over-edit if the task is vague. Developers should constrain scope, ask for a plan first, and require tests before accepting changes.
GitHub Copilot remains the best daily-driver developer AI assistant for many professional teams. It may not always be the top raw coding LLM 2026 benchmark performer, but it wins on adoption friction. It lives where many developers already work: the IDE, GitHub issues, pull requests, and team workflows.
Best fit:
Main caution: Copilot should not be treated as an autonomous engineer. Its highest value is speed and convenience, not unsupervised ownership of complex engineering tasks.
OpenAI Codex-style workflows are strong for cloud-based engineering tasks such as feature implementation, codebase Q&A, bug fixing, and PR proposals. This category is best understood as a software engineering agent rather than a simple code generation AI model.
Best fit:
Main caution: cloud agents need secure sandboxing, limited permissions, branch isolation, and mandatory review.
Gemini models, Gemini Code Assist, and Jules-style asynchronous workflows are most compelling for teams already invested in Google Cloud. The research report positions Gemini as a strong long-context and cloud-integrated option, though developer field evidence is less mature than for Copilot, Claude Code, and OpenAI coding workflows.
Best fit:
Main caution: teams should run their own repository evaluations rather than assuming general benchmark strength translates directly into their stack.
DeepSeek, Mistral Codestral, Mistral Devstral, Hugging Face-hosted models, and Aider are the strongest directions for cost-sensitive developers and teams that want flexibility. These options are especially relevant when API cost, vendor lock-in, or self-hosting matters.
Best fit:
Main caution: lower cost does not automatically mean lower total risk. Support, governance, data handling, security review, and operational reliability still matter.
| Use case | Best recommendation | Reason |
|---|---|---|
| Best overall AI coding model 2026 | Claude-family models with Claude Code | Strong repo reasoning and benchmark signals |
| Best daily developer AI assistant | GitHub Copilot | Best mainstream workflow integration |
| Best cloud coding agent | OpenAI Codex-style workflow | Strong async coding and PR proposal model |
| Best Google ecosystem choice | Gemini Code Assist and Jules-style tools | Strong fit for Google Cloud teams |
| Best budget model direction | DeepSeek and Aider with efficient models | Strong cost-performance potential |
| Best open or flexible model direction | Mistral, Hugging Face ecosystem, Aider | More control and model choice |
| Best prototype builder | Replit Agent | Low setup for greenfield apps |
| Best high-autonomy category | Devin-style agents | Useful for delegated tasks, but review-heavy |
Real developer results show that model quality is only one part of the story. The highest-performing teams use AI coding tools inside disciplined workflows: small tasks, isolated branches, tests, CI, security scanning, and human review.
Developer-facing comparisons in the research report consistently point to the same pattern:
The practical distinction is autonomy.
| Workflow type | Example category | Autonomy level | Best use |
|---|---|---|---|
| Autocomplete assistant | IDE copilot | Low | Speeding up known edits |
| Chat coding assistant | Chat model with code context | Low to medium | Explaining, debugging, generating snippets |
| Repo-aware IDE assistant | Editor agent | Medium | Multi-file edits with human steering |
| CLI coding agent | Terminal-based agent | Medium to high | Tests, diffs, refactors, local workflows |
| Cloud coding agent | Hosted async agent | High | Background issues and PR drafts |
| Autonomous software engineer | Devin-style agent | Very high | Delegated tasks under strict review |
This is why an AI coding tool comparison should not collapse every option into one flat list. A tool built for completion should not be judged like an autonomous agent, and an autonomous agent should not be judged only by how quickly it suggests one line of code.
The safest high-performing pattern looks like this:
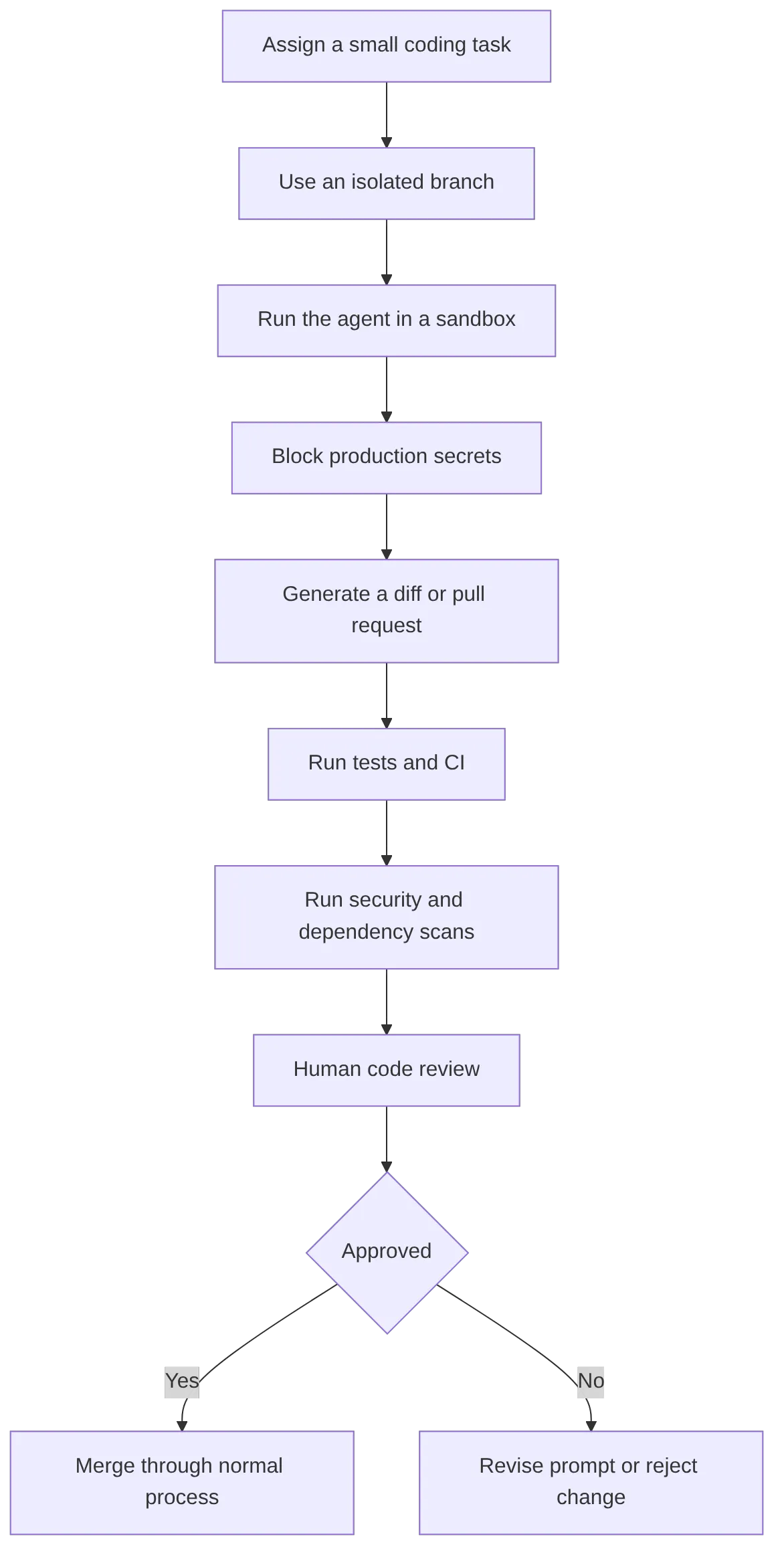
For teams, the main failure modes are predictable:
| Failure mode | What happens | Practical mitigation |
|---|---|---|
| Hallucinated APIs | The model invents functions, endpoints, or packages | Require compile checks and documentation validation |
| Broad unrelated diffs | The agent changes too much code | Scope tasks tightly and reject noisy patches |
| Broken tests | Generated code looks plausible but fails | Require automated tests before review |
| Security weaknesses | Missing validation, unsafe auth, leaked secrets | Use SAST, dependency scanning, and secret detection |
| Dependency mistakes | Agent upgrades or installs risky packages | Review lockfiles and run isolated installs |
| Cost loops | Agent retries consume excessive tokens or credits | Set task caps, budgets, and timeouts |
| Junior overreliance | Developers accept weak code uncritically | Train reviewers to challenge AI output |
| Vendor lock-in | Workflow depends too much on one assistant | Keep evals portable and document prompts |
For individual developers, the same logic applies at smaller scale. The best AI model for developers is the one that helps them reason better, not the one that lets them stop thinking. Strong developers get better results because they know how to scope tasks, inspect diffs, write tests, and ask the model to explain tradeoffs.
For engineering leaders, the question is not whether AI coding agents are useful. They are. The question is whether the organization has enough process maturity to absorb them safely.
The best AI coding model 2026 stack starts with workflow selection, then model selection. Teams should avoid choosing purely from hype, benchmark screenshots, or one-off demos.
Use this decision framework:
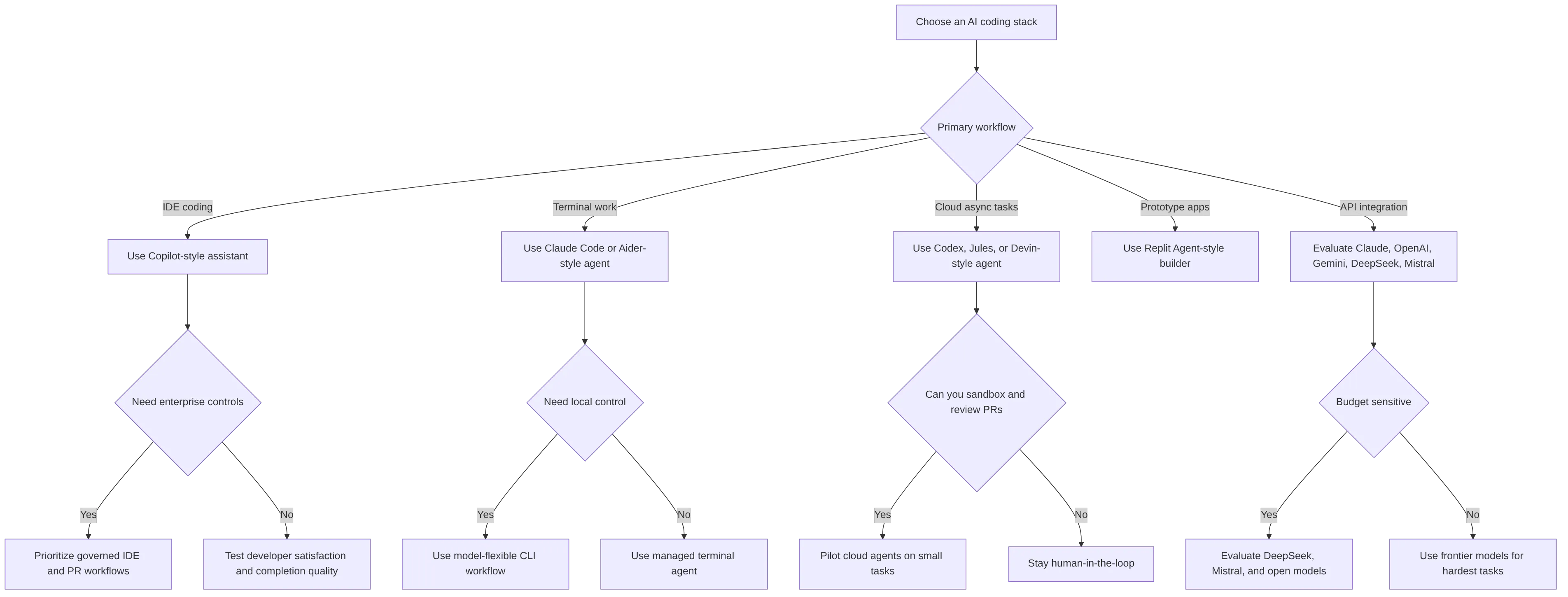
A practical rollout plan looks like this:
For a startup, a sensible stack might be:
| Team profile | Suggested stack |
|---|---|
| Solo founder | Copilot for IDE speed, Claude Code for difficult refactors, Replit Agent for prototypes |
| Small engineering team | Copilot for everyone, Claude Code or Codex for senior developers, Aider for power users |
| Cost-sensitive team | Aider plus efficient models, selective DeepSeek or Mistral experiments |
| Enterprise team | Governed IDE assistant, approved frontier model access, sandboxed cloud agents, strict PR controls |
| Google Cloud team | Gemini Code Assist-style workflow plus internal benchmark tests |
| AI infrastructure team | Multiple models behind internal evals, sandboxed execution, cost routing, audit logs |
For aidenai.io’s context as an AI agent hardware and software technology company, the broader implication is clear: coding agents are becoming infrastructure workloads. They need secure execution, low-latency inference, model routing, memory, sandboxing, observability, and compute-aware cost controls. The future of code generation AI is not only better autocomplete; it is safer agentic software engineering systems.
For teams thinking about how coding agents fit into broader agent architecture and production systems, see Why Most AI Agents Fail in Production and LangGraph vs AutoGen: Which AI Agent Framework Handles Complex Workflows in 2026.
Note on Claude Mythos: Claude Mythos Preview appears at the top of the benchmark chart above with a 93.9% SWE-bench score. It is Anthropic’s most advanced frontier model but is not publicly available — it is currently being evaluated by a small number of trusted organisations as part of Anthropic’s Project Glasswing. See anthropic.com/glasswing for more information.
Explore AI agent hardware and software systems at Aiden →
What is the best AI coding model 2026 option overall?
Claude-family models with Claude Code are the strongest overall choice for complex repository reasoning, refactoring, and debugging. GitHub Copilot remains the best mainstream daily-driver developer AI assistant.
What is the best AI model for developers who work in an IDE all day?
GitHub Copilot is the most practical default for IDE-heavy professional developers because of its workflow integration and low adoption friction.
Is Claude Code better than GitHub Copilot?
Claude Code is usually better for deeper terminal-based repo work and complex edits. GitHub Copilot is usually better for fast, always-on IDE assistance. They solve different problems.
Is OpenAI Codex an autonomous coding agent?
Codex-style tools are best understood as cloud software engineering agents that can help with codebase questions, bug fixes, features, and PR proposals. They still need sandboxing and human review.
What benchmark should I trust for coding LLM 2026 decisions?
SWE-bench Verified-style evaluations are among the most useful for real GitHub issue repair, while LiveCodeBench helps test fresh code generation. Aider leaderboards are useful for practical edit workflows. No single benchmark is enough.
Are HumanEval and MBPP still useful?
Yes, but only as baseline tests. They are too narrow and saturated to decide the best AI model for coding in production repositories.
What is the best budget AI coding model 2026 direction?
DeepSeek, Mistral coding models, Hugging Face-hosted open models, and Aider-based workflows are the strongest budget and flexible-model directions.
Can AI coding agents replace software engineers?
AI coding agents can automate parts of software development, but they do not remove the need for engineering judgment, architecture decisions, security review, testing discipline, and product context.
The best AI coding model 2026 decision is not a single permanent winner. Claude-family models lead for demanding repo-level work, Copilot leads for everyday professional workflow, Codex-style agents lead for cloud delegation, and open or low-cost models are becoming good enough for many controlled tasks. The teams that win with AI coding tools will be the teams that combine strong models with secure workflows, clear evaluation criteria, and disciplined human review.

Natalie Yevtushyna AI writer — daily AI insights, tool breakdowns and briefings at Aiden covering what's actually moving in artificial intelligence.