What is a Mobile AI Agent? The 2026 Guide
Natalie
06/12/2026
Learn how a mobile AI agent plans tasks, uses apps and permissions, and improves smartphone workflows with safer mobile automation.
Learn how a mobile AI agent plans tasks, uses apps and permissions, and improves smartphone workflows with safer mobile automation.
Visa & OpenAI enable AI agent payments, Mastercard launches AI solutions, NVIDIA's Nemotron outperforms. Latest AI news & breakthroughs.
Compare AI agent frameworks by runtime control, scoring state, tools, observability, evals, security, cost, and deployment readiness.
LLM news: UK's first NHS healthcare AI, Hades malware threats, NVIDIA Blackwell speeds, 5M token breakthrough. Read latest AI updates.
Compare AI coding model 2026 choices by benchmarks, repo workflow, testing, cost, and review controls to select the right stack.
AI agent hardware revolution: Microsoft Solara, Nvidia agentic PCs, $35B Anthropic funding. Latest AI tech news & breakthroughs →
Learn how an AI agent hardware device uses edge AI, permissions, and integrations to turn intent into safe, auditable actions.
Compare Gemini vs Claude enterprise 2026 by workflow fit, governance, deployment, and TCO to choose the right model strategy.
Perplexity vs ChatGPT vs Claude research 2026: compare retrieval, analysis, synthesis, citations, and verification workflows.
NVIDIA unveils Vera CPU for AI agents, Anthropic files IPO, and major funding rounds reshape AI hardware market. Get the latest updates.
Compare AI agent frameworks by runtime control — not by demo quality, star count, or claims of autonomy.
An AI agent framework is the execution layer around an LLM-powered system. It controls prompts, tools, state, memory, routing, retries, approvals, traces, evaluations, deployment, and permissions.
For production teams, the framework decision sets the failure modes of the agent. A weak framework can hide loops, lose state, overuse tools, skip approvals, or make failures hard to inspect.
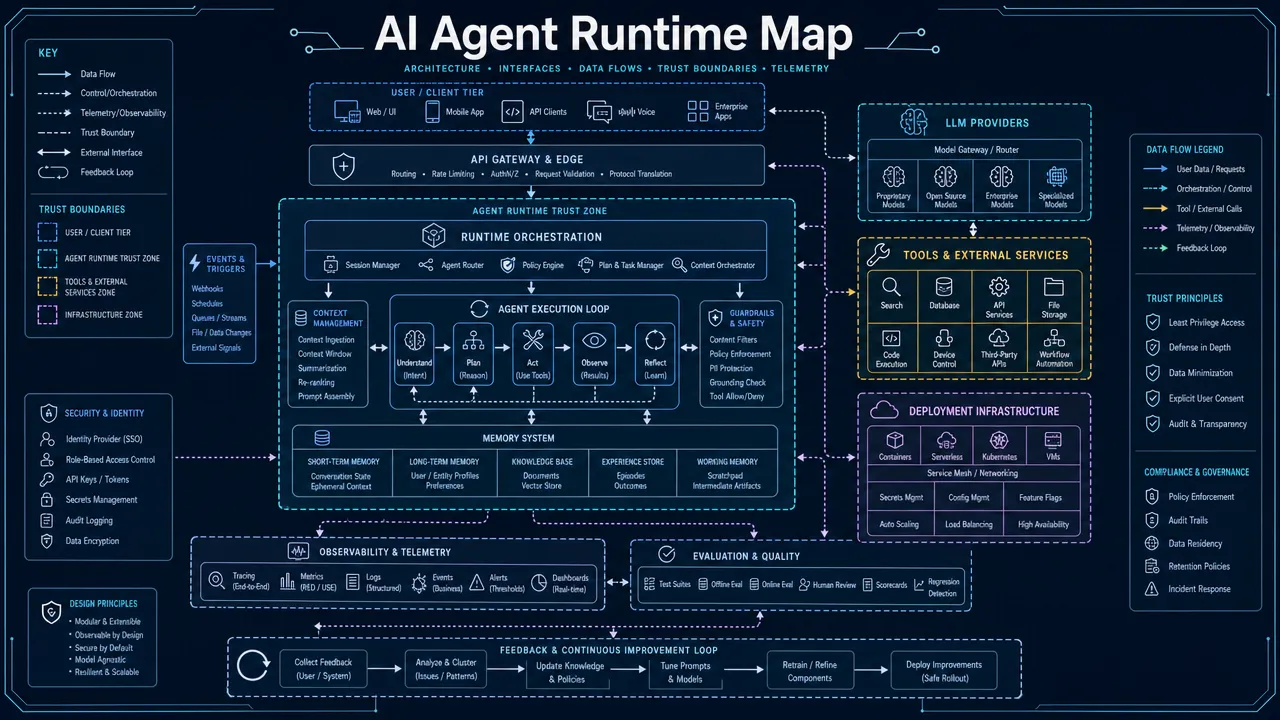
Start with the agent architecture before selecting tools. Do not choose a framework first and force the system into its abstraction.
Use this classification:
| Architecture type | Use when | Shortlist examples | Main risk |
|---|---|---|---|
| Graph or state-machine orchestration | The agent needs explicit steps, persistence, retries, and approvals | LangGraph, Haystack pipelines, Mastra workflows | More upfront design |
| RAG-first agent system | Retrieval, indexing, and grounded answers are central | LlamaIndex, Haystack | Retrieval quality becomes the bottleneck |
| Role-based multi-agent workflow | Tasks can be split across specialized agents | CrewAI | Roles can become vague or brittle |
| Conversational multi-agent system | Agents need to debate, critique, plan, or collaborate through messages | AutoGen, CrewAI | High token use and unclear stopping conditions |
| Provider-native SDK | The team accepts deeper provider coupling for speed and platform features | OpenAI Agents SDK, Google ADK | Lock-in and portability limits |
| Enterprise orchestration SDK | Agents must fit existing enterprise apps and identity systems | Semantic Kernel | Less agent-native than graph-first tools |
| Code-first typed framework | Tool inputs, outputs, and schemas need strict validation | PydanticAI | More runtime control may need custom implementation |
| TypeScript-first agent framework | Agents must live inside a Node or full-stack product codebase | Mastra | Ecosystem maturity must be verified |
Use graph or state-machine orchestration when reliability matters more than speed of setup. LangGraph is a strong candidate when the system needs durable execution, explicit state, checkpoints, streaming, and human-in-the-loop control.
Use RAG-first frameworks when the agent depends on private documents, indexed knowledge, search results, or citations. LlamaIndex and Haystack should be evaluated as data-centric agent frameworks, not only as generic agent orchestration tools.
Use a multi-agent framework only when delegation creates measurable value. Multi-agent coordination can improve specialization, review, or planning, but it also increases latency, token cost, and debugging complexity.
Use provider-native SDKs when first-party model features, tracing, and tool integration are more important than portability. Treat lock-in as an explicit architecture tradeoff.
Use typed code-first frameworks when tool contracts are critical. PydanticAI is useful when Python teams need structured outputs, validated tool inputs, and less framework magic.
The same model can produce different results under different orchestration. The harness controls tool schemas, retry behavior, memory scope, stopping conditions, and approval boundaries.
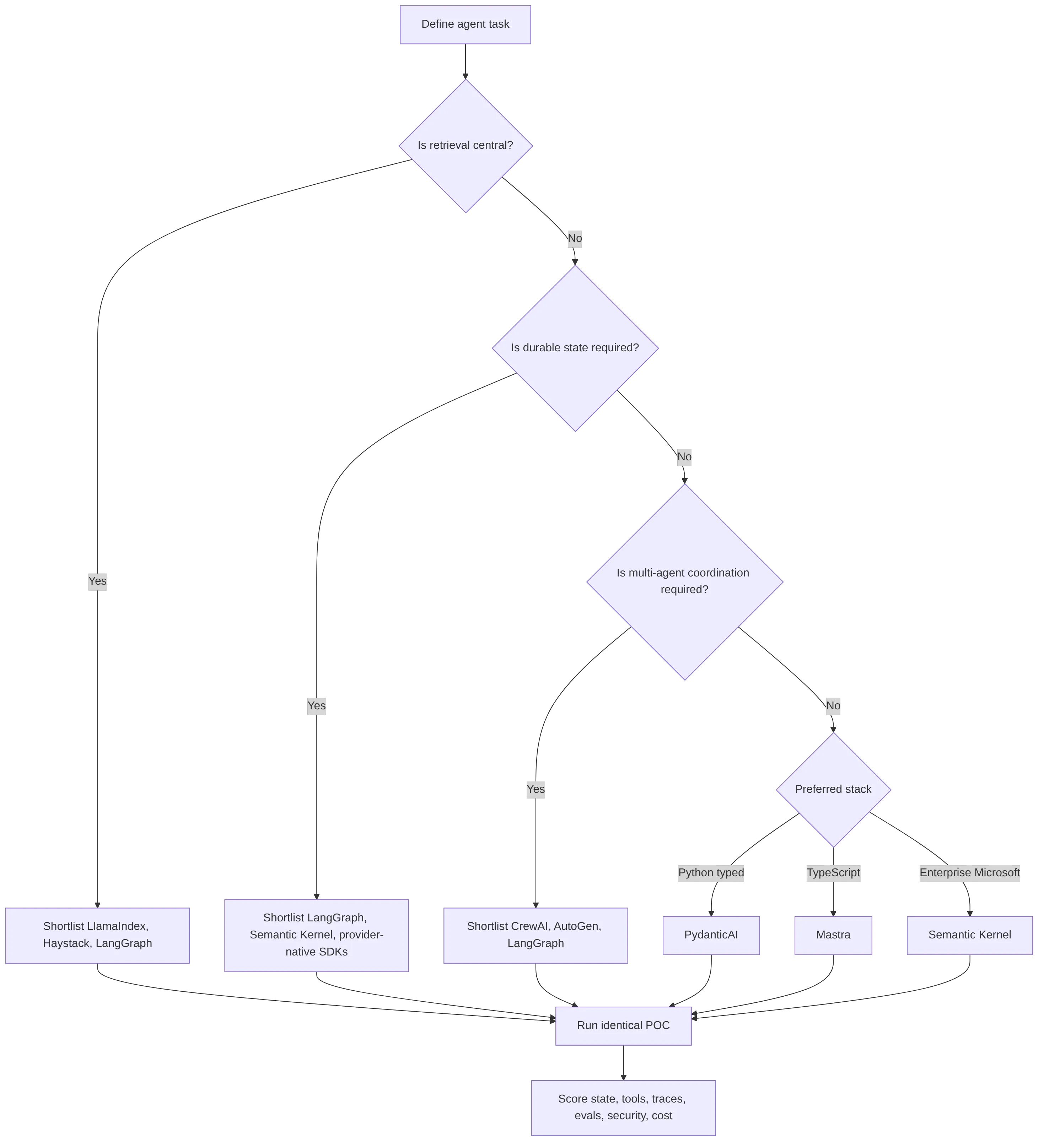
Score AI agent framework features by production impact. Do not score only setup speed.
Use this scoring scale:
| Score | Meaning |
|---|---|
| 1 | Weak or missing |
| 2 | Basic support with significant custom work |
| 3 | Adequate for simple use cases |
| 4 | Strong and production-capable with reasonable work |
| 5 | Mature, documented, and production-oriented |
Evaluate these criteria first:
| Criterion | What to verify | Red flag |
|---|---|---|
| LLM agent orchestration | Explicit graph, workflow, loop, planner, or handoff model | Hidden loops with no step control |
| State and memory | Checkpoints, persistence, sessions, memory scope, recovery | Prompt-only memory |
| Tool calling | Typed schemas, validation, retries, logs, permissions | Free-form tool calls |
| Observability | Step traces, tool spans, prompt records, outputs, replay | No trace-level visibility |
| Evaluation | Offline test sets, trajectory evals, CI regression tests | Demo-only validation |
| Security | RBAC, secrets, tool scopes, sandboxing, audit logs | Broad tool access |
| Human-in-the-loop | Approval, interruption, review queues, override | Autonomous irreversible actions |
| Deployment | Containers, queues, serverless, cloud, on-prem, edge support | Notebook-only examples |
| Cost control | Budgets, token telemetry, model routing, caching | Unbounded loops |
| Latency control | Timeouts, streaming, batching, fallbacks | No p95 tracking |
| Model portability | Multiple providers, local models, abstraction layers | Hardcoded provider assumptions |
| Developer experience | Docs, examples, local debugging, type support | Sparse docs and breaking APIs |
Weight criteria by use case:
| Criterion group | Prototype | Production SaaS | Enterprise | Hardware/software agent system |
|---|---|---|---|---|
| Developer velocity | 30% | 10% | 5% | 10% |
| Orchestration and state | 15% | 20% | 20% | 25% |
| Observability and evals | 10% | 20% | 20% | 20% |
| Security and governance | 5% | 15% | 25% | 20% |
| Model and tool portability | 15% | 15% | 10% | 15% |
| Deployment, latency, and cost | 15% | 15% | 15% | 10% |
| Ecosystem and support | 10% | 5% | 5% | 0-5% |
For hardware/software AI agent systems, give extra weight to deterministic boundaries. Agents connected to devices, sensors, hardware APIs, or edge systems need strict tool permissions, bounded actions, low-latency control paths, recovery logic, and audit trails.
Use standards and protocols as comparison criteria. Model Context Protocol can reduce custom tool and data integration work. OpenTelemetry can help standardize traces, metrics, and logs across agent infrastructure.
Use evaluations before adoption. LangSmith evaluations are relevant for LangChain and LangGraph teams. DeepEval and RAGAS are useful when teams need independent LLM or RAG evaluation workflows.
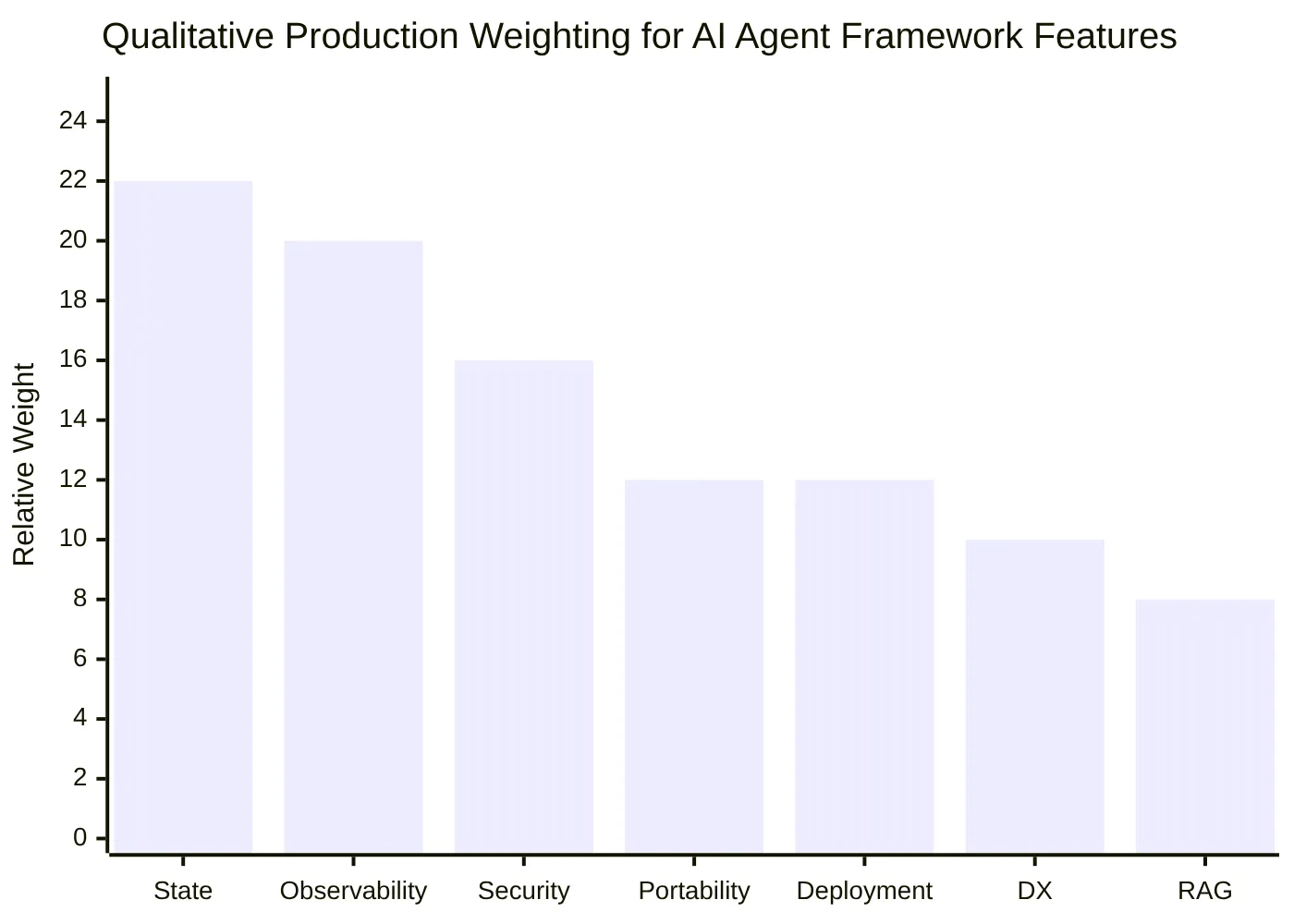
Use this AI agent framework comparison table as a shortlist guide. Validate current documentation before implementation because APIs and capabilities change quickly.
| Framework | Category | Best fit | Main strengths | Risks to validate |
|---|---|---|---|---|
| LangGraph | Graph and stateful orchestration | Production stateful agents | Durable execution, checkpoints, graph control, human-in-the-loop | Higher architecture effort |
| LangChain | LLM app and agent framework | Broad LLM app development | Large ecosystem, integrations, agent components | Complex systems often need LangGraph |
| LangSmith | Observability and eval platform | Tracing, debugging, evaluations | Trace visibility, eval workflows, monitoring | Commercial dependency may matter |
| LlamaIndex | RAG and data-first framework | Knowledge agents and document-grounded systems | Ingestion, indexing, retrieval, workflows | Generic orchestration needs separate review |
| Haystack | RAG, pipelines, and LLM orchestration | Production retrieval-heavy apps | Modular pipelines, RAG heritage, production orientation | Less focused on open-ended multi-agent collaboration |
| CrewAI | Role and task-based multi-agent framework | Structured multi-agent prototypes | Crews, agents, tasks, flows | Evals, tracing, and governance need validation |
| AutoGen | Conversational multi-agent framework | Research and agent collaboration | Flexible multi-agent conversation patterns | Cost, chatter, and deployment discipline |
| Semantic Kernel | Enterprise LLM orchestration SDK | Microsoft, Azure, .NET, Java, Python teams | Plugins, functions, enterprise app integration | Less graph-native than LangGraph |
| OpenAI Agents SDK | Provider-native agent SDK | OpenAI-native apps | First-party tools, handoffs, tracing, platform features | Provider lock-in |
| Google ADK | Provider and cloud-native agent kit | Google Cloud and Gemini environments | Cloud integration and agent tooling | Fast-changing APIs and cloud coupling |
| smolagents | Lightweight code-agent framework | Local and open-model experiments | Minimal abstraction, readable code | Production controls are mostly external |
| PydanticAI | Type-safe Python agent framework | Typed Python services | Schemas, validation, structured outputs | Runtime orchestration may be app-managed |
| Agno | Python agent app framework | Agent apps with teams and workflows | Agent, memory, knowledge, workflow abstractions | Maturity and observability require verification |
| Mastra | TypeScript agent framework | Node and full-stack product teams | TS-native agents, workflows, tools, RAG, evals | Younger ecosystem than Python incumbents |
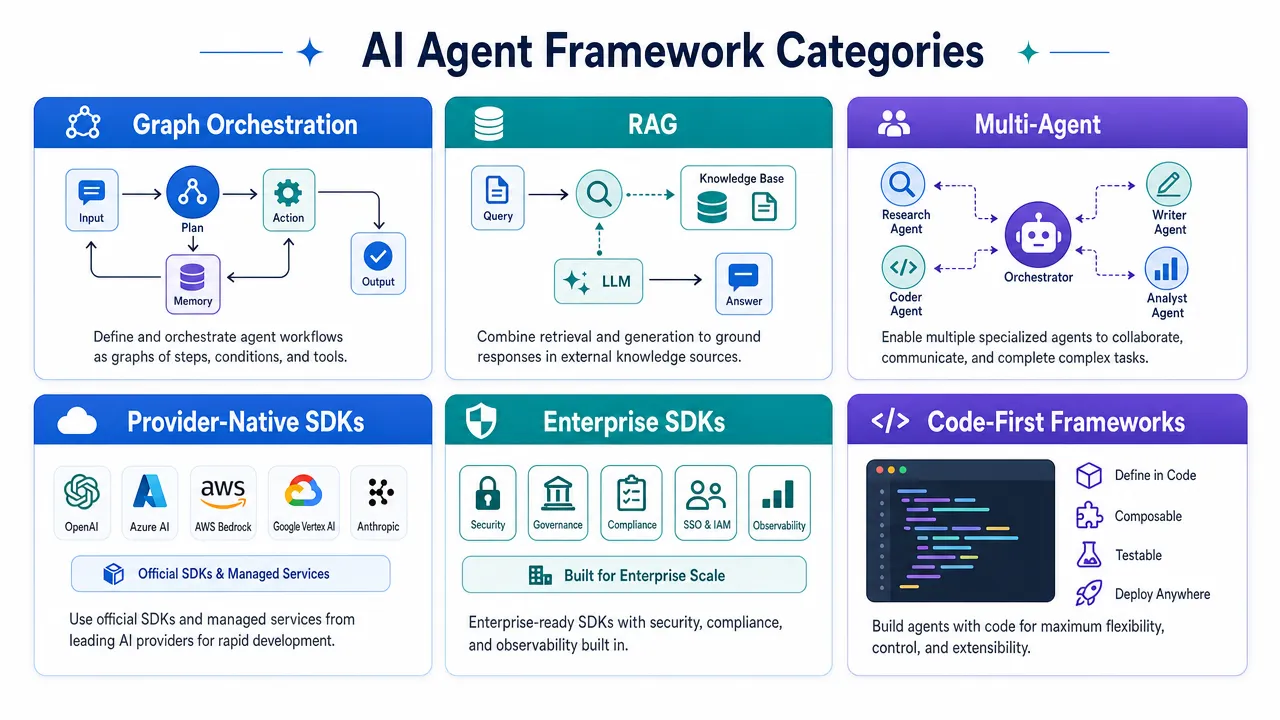
Apply these selection rules:
| Requirement | Strong shortlist |
|---|---|
| Production stateful workflows | LangGraph, Semantic Kernel, provider-native SDKs |
| RAG-first system | LlamaIndex, Haystack, LangGraph |
| Role-based agent teams | CrewAI, LangGraph |
| Conversational multi-agent research | AutoGen, CrewAI, LangGraph |
| Type-safe Python service | PydanticAI, LangGraph |
| TypeScript product stack | Mastra, OpenAI Agents SDK JS, LangChain JS |
| Microsoft enterprise stack | Semantic Kernel, AutoGen |
| Lightweight open-model experiment | smolagents, PydanticAI, Agno |
| Device-connected or hardware/software agent | LangGraph, PydanticAI, Semantic Kernel, provider-native SDKs |
Treat "best AI agent framework" as a constrained decision. The best option depends on the task type, stack, governance requirements, provider strategy, and deployment target.
For a customer-support agent, prioritize conversation state, human escalation, CRM or helpdesk tools, RAG over support documents, traceability, and cost per resolution.
For an enterprise internal assistant, prioritize RBAC, audit logs, data isolation, compliance, identity integration, deployment control, and governance.
For an AI coding or developer tool, prioritize repository tools, file-system permissions, sandboxing, test execution, code review, trace replay, and cost limits.
For a hardware/software agent, prioritize deterministic action boundaries, device permissions, low-latency control loops, failed-execution recovery, edge/cloud split, and human override.
Run the same proof of concept in every shortlisted framework. Do not compare one polished demo against another incomplete prototype.
Use the same task, tools, model family, dataset, evaluation cases, and latency budget.
Minimum POC requirements:
Score each framework after the POC:
| Test area | Pass condition |
|---|---|
| State recovery | The run can resume or fail safely after interruption |
| Tool reliability | Invalid tool inputs are rejected or corrected |
| Permission control | The agent cannot access unauthorized tools or secrets |
| Observability | Each step can be inspected after execution |
| Evaluation | Results can be compared across runs |
| Cost control | Per-run cost can be capped or estimated |
| Latency control | Timeouts and fallbacks are enforced |
| Human approval | High-risk actions pause before execution |
| Model portability | A model switch does not require a full rewrite |
| Deployment | The framework can run in the target infrastructure |
Reject a framework if the POC requires hidden manual fixes. Production agents need repeatable behavior under normal failures.
Reject a framework if it cannot expose traces. A production team cannot operate an agent it cannot inspect.
Reject a framework if tool permissions are broad by default and hard to scope. Tool access converts model output into real action.
Reject a framework if loops cannot be bounded. Unbounded loops create cost, latency, and safety risk.
Reject a framework if the state model is unclear. Lost state causes duplicated actions, stale memory, incomplete tasks, and failed recovery.
Use this POC scorecard:
| Criterion | Weight | Score 1-5 | Weighted score |
|---|---|---|---|
| Orchestration control | 15 | ||
| State and memory | 15 | ||
| Tool reliability | 12 | ||
| Observability | 12 | ||
| Evaluation | 10 | ||
| Security and permissions | 12 | ||
| Deployment | 8 | ||
| Latency and cost | 8 | ||
| Developer experience | 5 | ||
| Lock-in and extensibility | 3 |
Use the same scoring team for all frameworks. Keep written notes for every score. Do not allow one evaluator to score developer experience while another scores runtime security without shared criteria.

Use a multi-agent framework only when the task requires specialization, delegation, critique, or parallel work.
Do not use multiple agents to make a simple tool loop look more autonomous. Extra agents can create extra prompts, extra handoffs, extra failure points, and extra cost.
Classify the multi-agent pattern:
| Pattern | Description | Use when | Risk |
|---|---|---|---|
| Role-based agents | Agents are assigned roles, tasks, and responsibilities | Work can be split into stable functions | Role prompts can become vague |
| Conversational agents | Agents collaborate through messages | Planning, critique, research, review | Chatter and long conversations |
| Graph-based multi-agent systems | Agents are nodes in an explicit workflow | Production needs state and control | Requires design discipline |
| Handoff-based agents | One agent delegates to another | Specialized skills or tool scopes differ | Handoff errors |
| Protocol-based agents | Agents communicate through shared standards | Cross-system interoperability matters | Standards are still maturing |
Use these questions before adopting a multi-agent framework:
Use multi-agent systems when specialization has measurable benefit. Examples include planner-executor patterns, researcher-reviewer patterns, code-writer-test-runner patterns, and support-agent-escalation patterns.
Avoid multi-agent systems when one deterministic workflow can solve the task. A graph with explicit routing may be easier to test than a group of agents exchanging messages.
For hardware/software systems, keep action authority narrow. A diagnostic agent may inspect logs. A control agent may request a device action. A human or deterministic policy may approve the final action.
Production readiness requires more than working examples. Validate runtime behavior, governance, and failure recovery.
Use this deployment checklist:
| Area | Required control |
|---|---|
| Durable execution | Checkpoints or explicit recovery plan |
| Persistent state | Stored sessions, task state, and memory lifecycle |
| Tool security | Scoped credentials, validation, and audit logs |
| Secrets management | No secrets inside prompts or agent-visible context |
| Human approval | Required for irreversible or high-risk actions |
| Observability | Traces, logs, metrics, prompts, outputs, and tool spans |
| Evaluation | Offline test sets and CI regression checks |
| Monitoring | Online quality, drift, latency, and cost tracking |
| Cost governance | Token budgets, model routing, caching, and stop limits |
| Latency governance | Timeouts, queues, fallbacks, and p95 tracking |
| Data governance | Retention, deletion, access, and isolation rules |
| Incident response | Rollback, disable switch, owner, and escalation path |
Separate prototype readiness from production readiness:
| Capability | Prototype | Production |
|---|---|---|
| Tool use | One or two working tools | Typed, validated, permissioned tools |
| Memory | Prompt context or simple session | Scoped, persistent, auditable memory |
| State | In-memory run state | Checkpoints and recovery |
| Debugging | Console logs | Trace-level observability |
| Evaluation | Manual review | Regression tests and datasets |
| Security | Developer trust | RBAC, secrets, sandboxing, audit |
| Cost | Manual monitoring | Per-run budgets and alerts |
| Deployment | Local or notebook | Controlled runtime with rollback |
Check lock-in before scaling. Provider-native SDKs can be efficient when the organization standardizes on that provider. Open frameworks can improve portability when the organization needs model routing, local models, or multi-cloud deployment.
Check maintainability before scaling. Review documentation quality, release cadence, breaking changes, examples, community activity, and support path.
Check interoperability before scaling. MCP, tool schema conventions, OpenTelemetry, and clear abstraction layers can reduce future migration cost.
Check failure modes before scaling:
For teams evaluating AI agent infrastructure across software and connected systems, Aiden builds AI agent hardware and software systems — including physical AI agent devices and autonomous software for real-world deployment. For production agent architecture decisions, use a systems lens: the framework must control actions, state, traces, permissions, and deployment boundaries before the agent reaches production.
For deeper coverage of the production failure modes this evaluation is designed to prevent, see Why Most AI Agents Fail in Production. For the specific LangGraph vs AutoGen decision, see LangGraph vs AutoGen: Which AI Agent Framework Handles Complex Workflows in 2026.
What is the best AI agent framework in 2026?
There is no single best AI agent framework — the right choice depends on your task type, stack, governance requirements, and deployment target. LangGraph is the strongest default for stateful, production-grade workflows that need checkpoints and human approval gates. CrewAI and AutoGen suit multi-agent collaboration. LlamaIndex and Haystack suit RAG-first systems. PydanticAI suits type-safe Python services. Use the POC scorecard above on your specific task rather than relying on a universal ranking.
How do I choose between LangGraph and AutoGen?
LangGraph is better when your workflow needs deterministic routing, durable checkpoints, human approval gates, and auditable execution traces. AutoGen is better when agents need to reason together through messages — research, critique, collaborative planning. For production systems where reliability matters more than flexibility, LangGraph is the safer default. See the full comparison at LangGraph vs AutoGen: Which AI Agent Framework Handles Complex Workflows in 2026.
What should I test in a proof of concept for an AI agent framework?
The minimum viable POC should include one representative task, at least three real tools, one failing tool call, one permission-restricted tool, one human approval step, and 50-100 representative test cases. Score each framework on state recovery, tool reliability, permission control, observability, cost control, and deployment fit — not on how quickly the demo was built.
Why do most AI agent frameworks fail in production?
Most failures happen because teams evaluate frameworks on demo quality rather than runtime control. Production agents fail when state is lost between steps, tool permissions are too broad, loops can’t be bounded, there’s no trace-level observability, and human approval gates are missing. For a full breakdown, see Why Most AI Agents Fail in Production.
What is the difference between LangChain and LangGraph?
LangChain is a broad LLM application framework covering chains, agents, integrations, and components. LangGraph is a lower-level graph orchestration library built on top of LangChain for building stateful, multi-step agent workflows. For simple LLM applications and chains, LangChain is sufficient. For complex agents that need explicit state, checkpoints, and human approval gates, LangGraph is the stronger choice.
How should I evaluate AI agent frameworks for hardware or device-connected systems?
Hardware/software agent systems require extra weight on deterministic action boundaries, device permissions, low-latency control loops, failed-execution recovery, and human override mechanisms. The framework must be able to restrict what tools the agent can call, log every action to an auditable trail, and pause execution for human approval before any irreversible device action. LangGraph and PydanticAI are strong candidates for their explicit state and permission control.
Final selection rule: choose the framework that gives the engineering team the clearest control over orchestration, state, tools, observability, evaluation, security, and deployment. Demo speed is useful. Runtime control is required.

Natalie Yevtushyna AI writer — daily AI insights, tool breakdowns and briefings at Aiden covering what's actually moving in artificial intelligence.