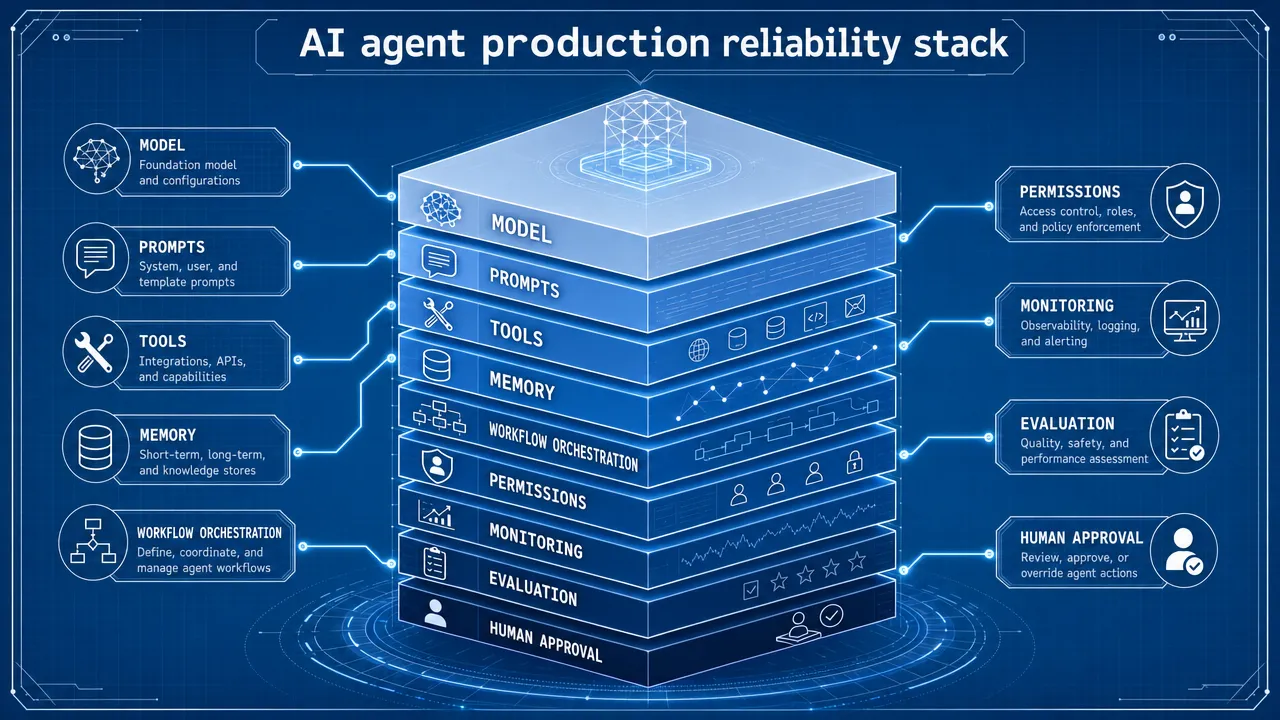
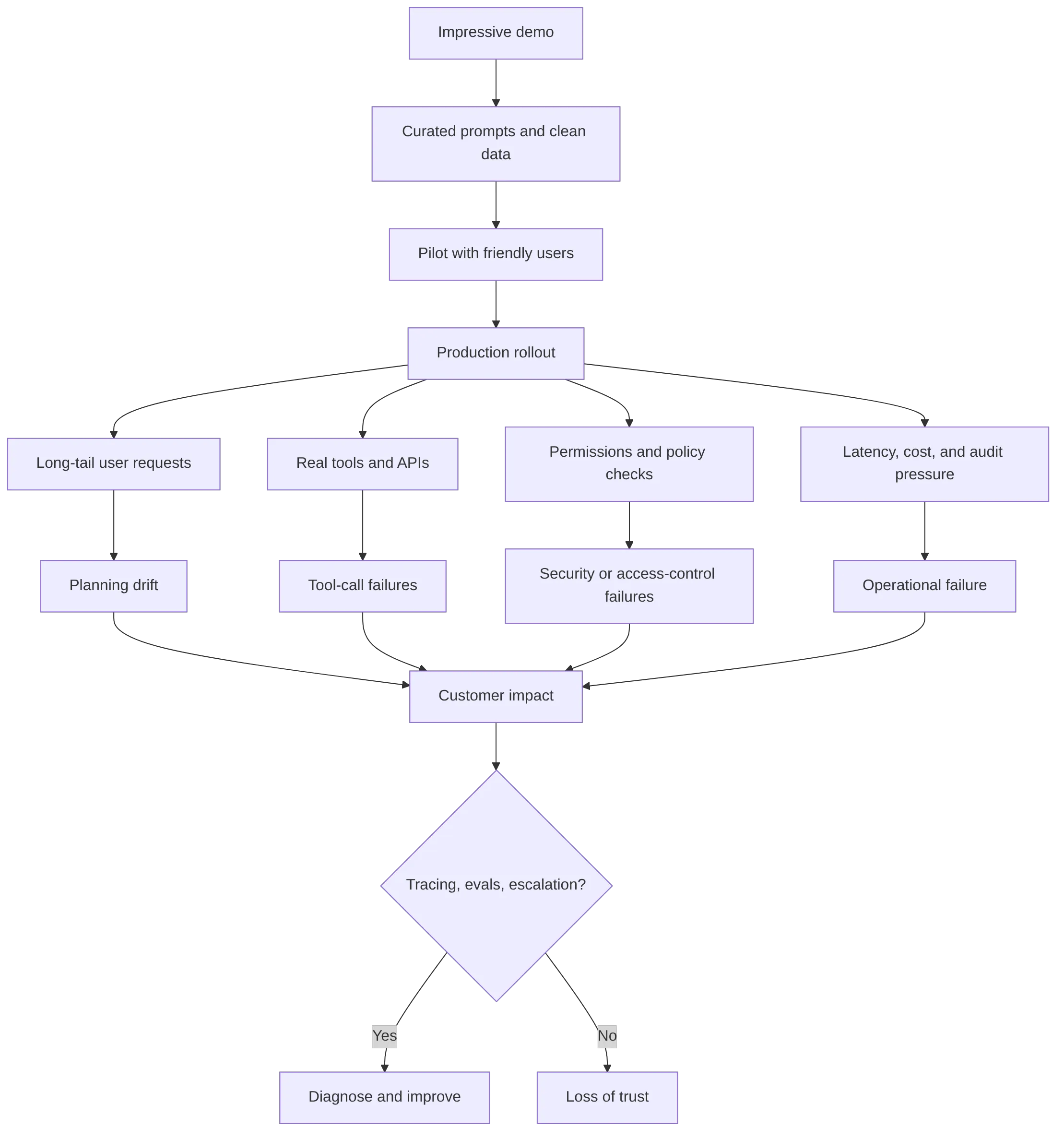
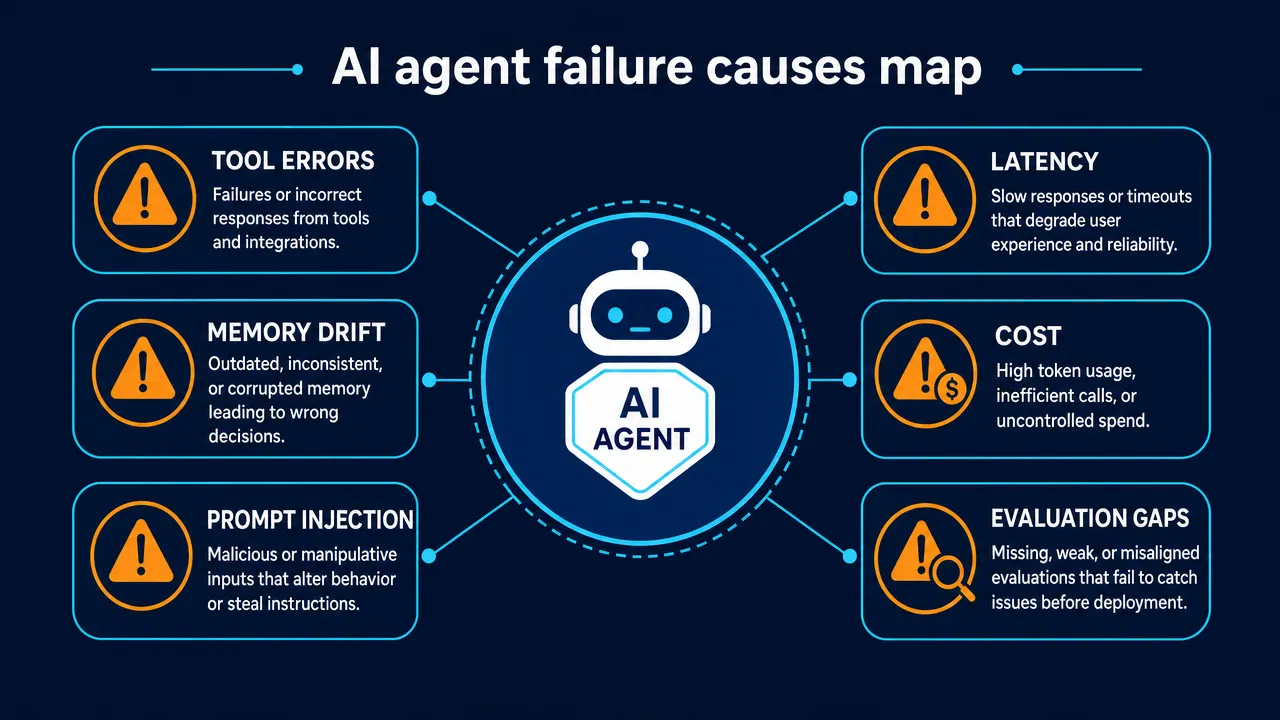
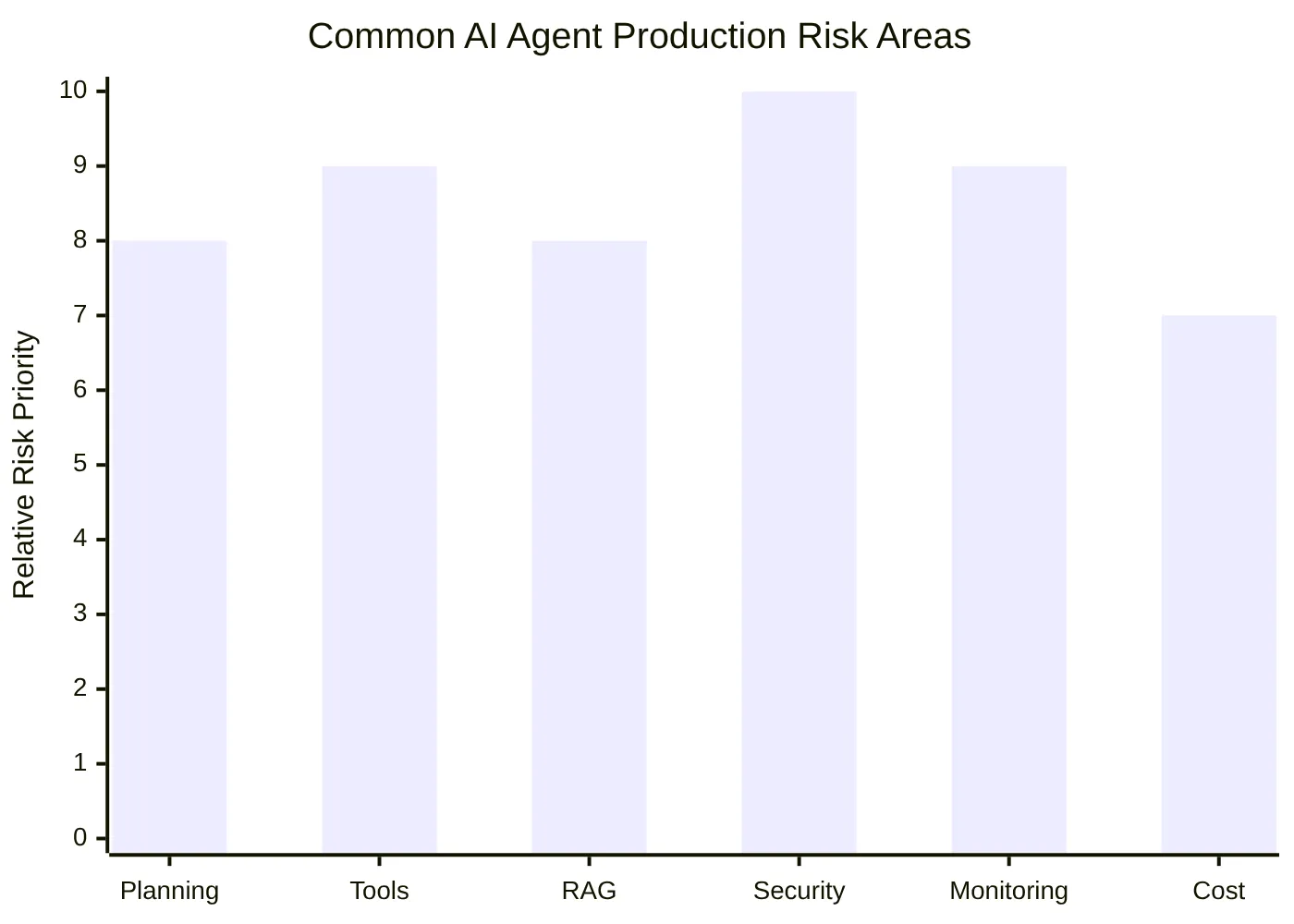
The Right to Interrupt: Building a Physical AI Agent You Can Actually Control
Natalie
07/20/2026
Interruptible AI agent design uses preemption, task cancellation, and context control to keep physical AI actions redirectable.